Delta Loading Using AWS Glue Job Bookmark and Dynamodb


Table of contents
There are few approaches to achieve the delta loading in AWS. I will be discussing more about the two option here;
Using Glue Job bookmark
Using dynamodb to read unprocessed file
Glue Job Bookmark
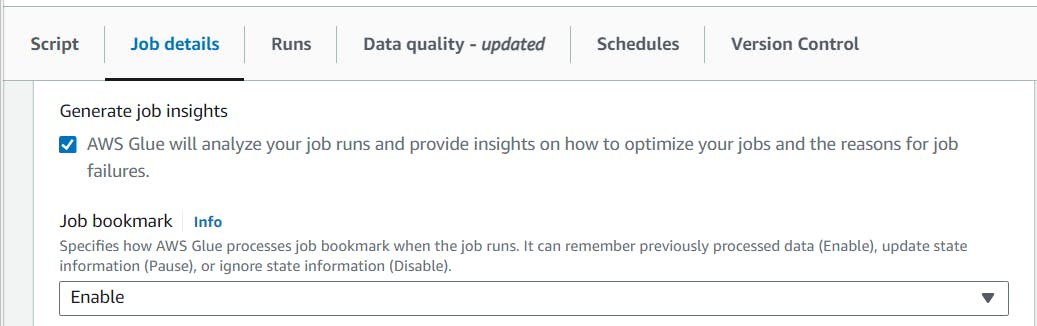
Using job bookmark, AWS glue tracks data that has previously been processed in a previous etl job run. Set the job bookmark to "enable" from the job details section to track the processed data and only process new data intake to the s3 location.
Create a dynamic frame from options using glueContext:
Set Job bookmark as Enable.
root_path = "s3://your-bucket-name/folder/"# read a CSV file from an S3 location from dynamic frame options csv_dynamicframe = glueContext.create_dynamic_frame.from_options( "s3", connection_options = { "paths": [root_path], }, format = "parquet", format_options = { 'withHeader': True }, transformation_ctx = "csv_dynamicframe", )And you can map the columns to the desired data types using Apply Mapping:

Now convert the dynamic frame to spark dataframe:

Now you can operate any spark function with "df", like "withColumn", or "aggregate functions", or write to s3 location or redshift using same dataframe(df).
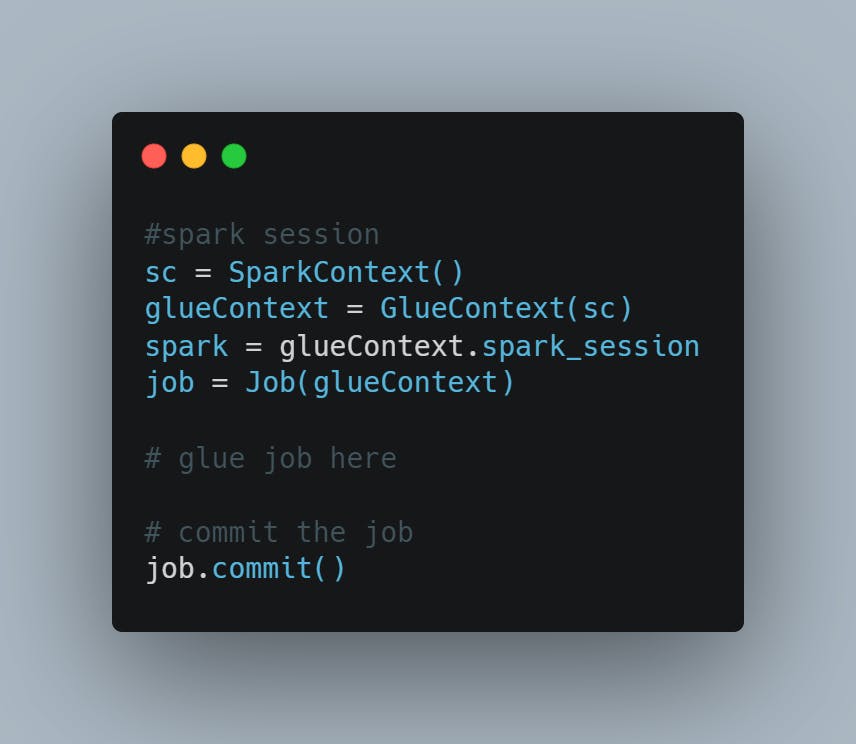
Job commit:
Glue job bookmark only works when is enabled and you have commit the job session you created in the starting:
Using Dynamodb to read unprocessed file
Amazon dynamodb is fully NoSQL database service that AWS provide with better performance and scalability.
We can use the dynamodb table to keep previously processed files from the s3 location and process only those that have not been stored.
Create a table in a dynamodb
Navigate to the Dyanodb service from aws console page, and then under the table section, you will find a button to create a table;

You can simply create a table, let's say: "processed_file_test"
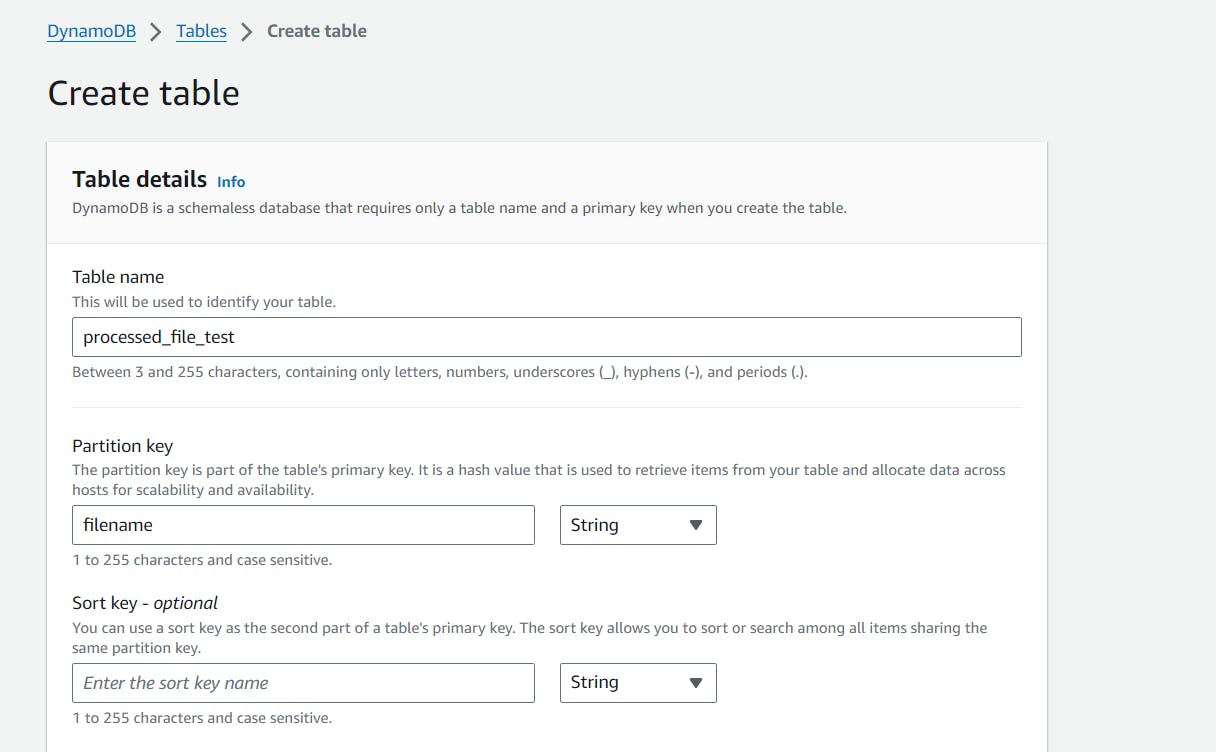
Under Create Table, you can give the name of your table which we will be using to store the processed filename, and a partition key as a table's primary key.
E.g, we will be creating the table name as, "processed_file_test", and "filename" as a partition key. Keep all other option as it is and create a table.
Create a boto3 client:

Create a empty list for the filenames for processing:

Identifying Unprocessed Files in an S3 bucket:
Extract filenames, checks their processing status in the table, and appends any unprocessed files to a list for further action.
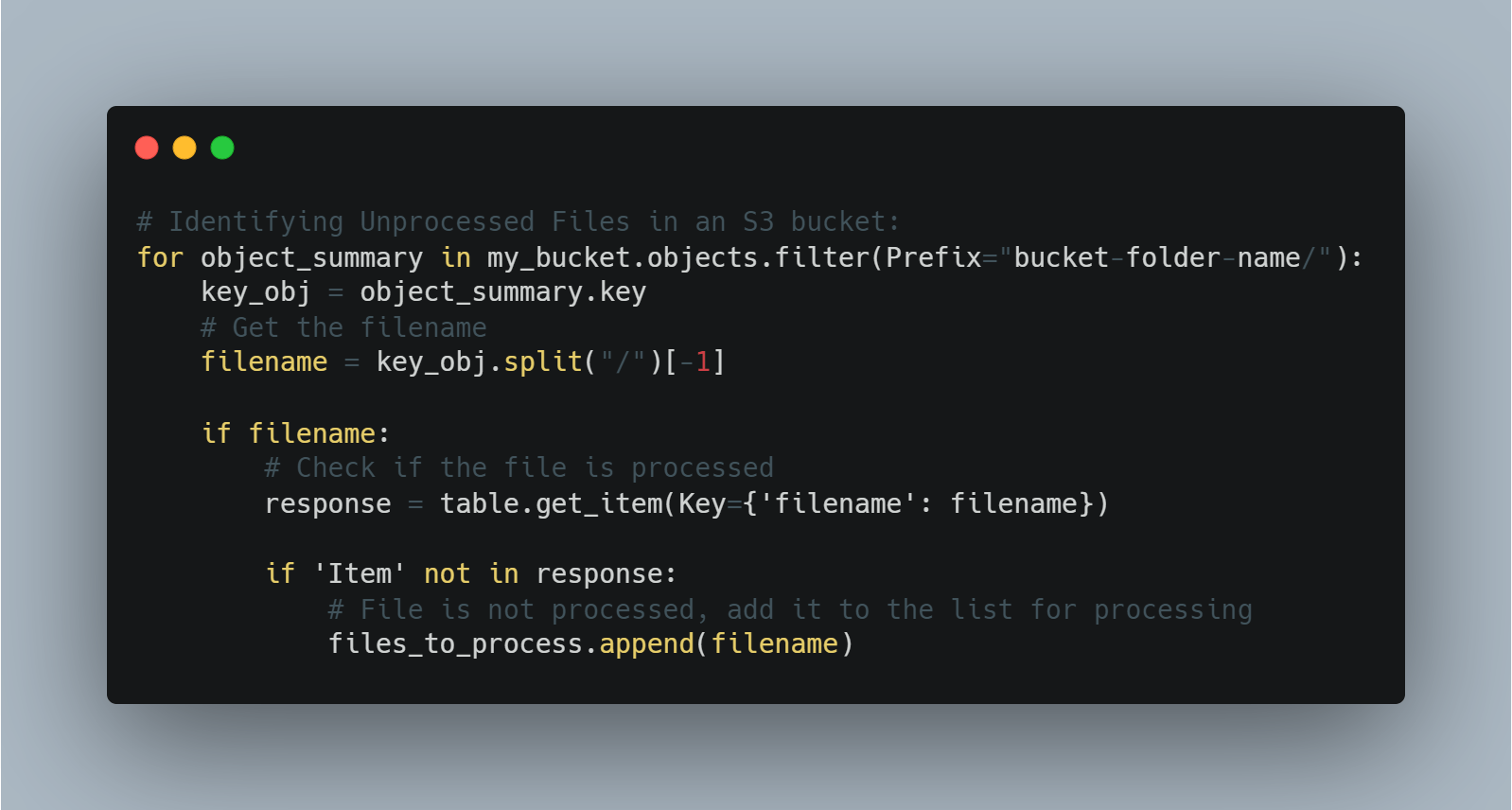
We just extract the filename and verify if it is already saved in the dynamodb table using dynamodb.get_item, where Key checks whether the extracted filename is already stored or not in the dynamodb table.
If 'Item' is not found in the dynamodb, it will simply append to the empty list we create to process the file name.
Process the file and store the name of file in dynamodb

This way, you can determine whether the file has already been processed or not, and if it has, skip that file because it has already been saved in the dynamodb table, and process only the unprocessed files.
Make sure the IAM role you used in the job has Dynamodb get_item and put_item access.
This way, using Glue Job Bookmark and Dyanamodb table, you can process the new data in AWS Glue.